いつの間にか、話題の動画生成モデル「WAN」が2.2へとアップデートされていた。早速、wan2.2_ti2v_5B_fp16.safetensorsを用いてテストを開始。結論から言うと、中量級VRAM環境(12GB前後)でも約720pクラスの高画質なi2v・t2v生成が現実的になった。
モデル構成:5Bと14Bの違い
まず前提として整理しておく。
| モデル | 構成 | VAE | モード | ファイルサイズ | 特徴 |
|---|---|---|---|---|---|
| WAN 2.2-14B | i2v / t2v 分離 + ハイノイズ&ローノイズ | VAE 2.1 | 二段階モデル | 約20GB以上 | 高精度だがVRAM要求が極大 |
| WAN 2.2-5B | i2v / t2v 統合 | VAE 2.2 | 混合単一モデル | 約10GB(fp16)/ 5GB(Q8) | 軽量・実用寄り |
注目すべきは5Bモデルがi2vとt2vの統合モデルとなっており、1ファイルで完結する点。また、VAEのバージョンが異なる点もポイントだ。5Bは新しいvae2.2を使うため、ComfyUIでの組み込み時にVAEとの非互換を起こさないよう注意が必要。
実行環境とメモリプロファイル
- GPU: RTX 4070 (VRAM 12GB)
- ComfyUI: 最新開発版(2025年7月時点)
- モデル構成:
wan2.2_ti2v_5B_q8.gguf+vae2.2
メモリ使用状況(推定値):
| モデル | 形式 | 実VRAM消費 |
|---|---|---|
| 5B FP16 | safetensors | 約12GB前後(ほぼ限界) |
| 5B Q8 | safetensors | 約9GB前後(安定動作) |
注意すべきはVAEデコード時のVRAMスパイク。通常のサンプリングは9GB内で収まるが、VAE変換フェーズで一時的に11.7GB以上まで跳ね上がり、プロンプトやシードによってフリーズすることが多い。
これを回避するため、ComfyUIノードを以下のようにカスタマイズ:
VAE Decodeノード → VRAM設定可能なノードに差し替え- Model Loderノード → distorch対応(gguf)ノードに置換
VRAM OFFLOAD→ 22GB指定(実際は6GB程度でOK)
ComfyUIワークフロー
ワークフローはComfyUIを最新にアップデートして提供のテンプレートからダウンロードして使った。
ComfyUIチームの更新の速さに頭が下がる。
そして少し手を加える。
まずはfp16モデルをggufのdistorchが使えるノードに変える。
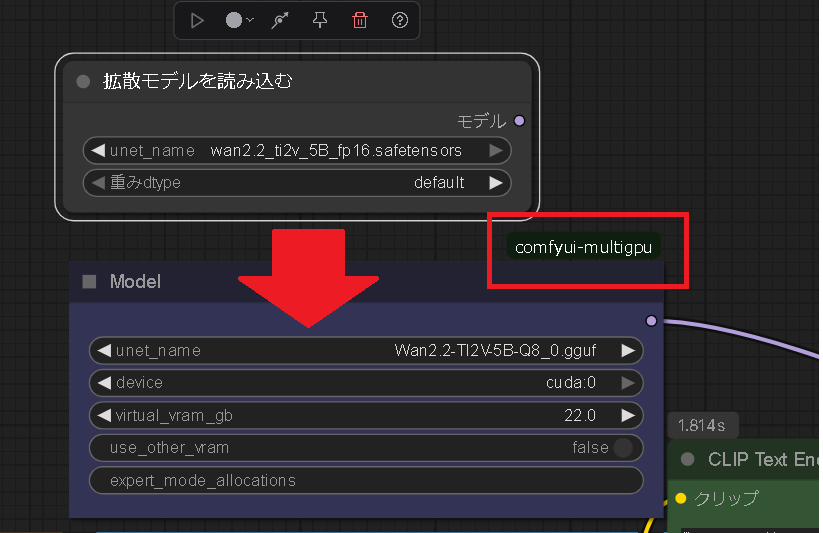
VRAM OFFLOADを22GBとしているがこれは自分のデフォルトでこのサイズのモデルであれば実際には5-6GBで十分だ。
ただwan2.2_ti2v_5B_q8.ggufは5GBのファイルサイズなのにサンプリングでVRAMを9GBも消費するのでこれまでのメモリ配置と異なっているかもしれない。
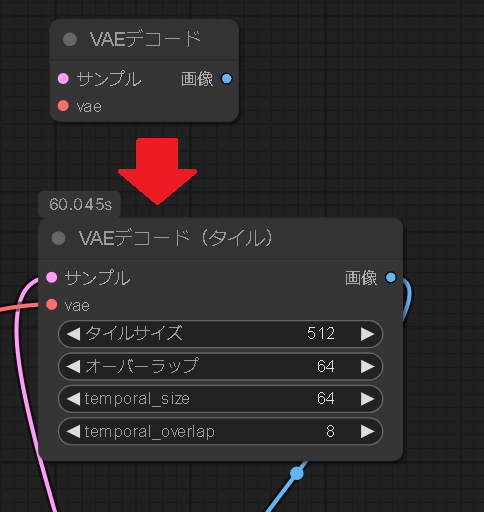
次に新しいVAE2.2が重いのか分からないがサンプリングした後に、VAEデコードフェーズでVRAMが11.7GBまで消費をして固まってしまうことが多いので設定変更できるVAEデコードのノードに変えて次の設定で使っている。
i2vの入力にしたオリジナル画像(Flux1-devの生成画像、生成でよく見る顔だ草)

出力条件と生成結果
- フレームサイズ:704×1280(縦長)
- フレーム数:89
- FPS:16
- モード:i2v(Image to Video)
比較対象として、WAN 2.1-14B(450×800)で生成した旧サンプルと並べてみた結果:
| 比較項目 | WAN2.1-14B | WAN2.2-5B |
|---|---|---|
| アクションの滑らかさ | ◎ | △(手先など崩れあり) |
| 解像度と精細感 | ◯ | ◎ |
| VRAM効率 | ×(20GB以上必要) | ◯(Q8で9GB) |
| モデルの統合性 | IとTで分離 | 統合型(TI2V) |
細部の動きは14Bの旧モデルに軍配が上がるが、720pがVRAM逼迫などで引っかかることなくサクサク作成できるのが強みだ。
その分I2Vの入力画像が高画質であればディテールがしっかり表現できる。
14BだとVRAM12GBの限界がQ6で500×900程度。
あと顔同一性維持も心なしか2.2-5Bの方が高そうだ。
一方で5BのT2Vはあまり期待しない方がいい。
プロンプトのみでいくつか出力したところやはり5Bモデルなんだと実感した。
LORA学習
- 手や細部モーションに課題はあるが、これは
Motion LoRAで補完可能 - 早速wan2.2のLoRAをレンタルGPU環境で学習予定
(しかし2025/7/31現在Musubi-tunerでは5Bは新しいvaeが通らずフェーズ1で、14Bはモデルが通らずフェーズ3でエラーでした。いずれ対応してくれるでしょう)
ちなみに、14BのQ5量子化モデルもサンプルを同じ変更して試行。生成できることはできる、しかし…
- 89フレームで40分以上の生成時間
- DisTorchしているせいかSTEP20のせいかとにかく時間がかかる
- 実用にはVRAM 50GB級(A100クラス)が必要と判断
WAN 2.2-5Bは、VRAM 8〜12GB帯で“画質と速度のバランスが取れた実用的生成AIモデル”としての地位を確立するだろう。とくにComfyUIを使ったノード設計次第で安定性も格段に向上。
高解像度・シームレスなt2v/i2v生成が可能となり、映像生成AIの敷居はさらに下がった。
wan2.2-14Bについてはwan2.1のSTEP20→6のように高速生成できれば話が変わってくるので、また有志の方が2.2用のCausVid、AccVid、RealismBoost、MPS、HPS2などのloraを作ってくれてモデルに統合されていくだろうから、それを待つことにしよう。
あと5Bモデルに関して、画像の多くの面積を動かした時に現れやすいフリッカーのような画面チカチカ問題は解決する必要がある。