先日までOpenAIのオープンモデルであるGPT-OSS 20B を試していましたが、日本語知識がかなり限定的で、実用には物足りないと感じていました。そんな中、西川善司氏の記事(PC Watch)で 64GB RAM + VRAM 16GB の環境で GPT-OSS 120B を動かした例が紹介されていたのを見つけ、「本当に動くのか?」と試してみることに。
私の環境は以下の通りでVRAMは更に少ないです。
- CPU RAM: 64GB
- GPU: RTX 4070(VRAM 12GB)
モデルのロード
openai/gpt-oss-120b(約 63.39GB)を LM Studio からダウンロードしてロードをスタートします。
CPU RAMはガッツリ64GB近くまで使い切ります。
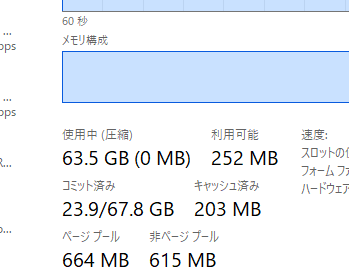
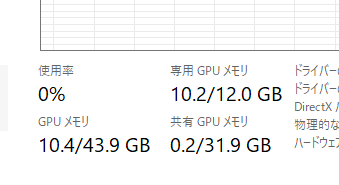
GPU RAMは約10GBでした。
LM Studioを使った方ならこのスクショでロードされていることがわかるはずです。
- 数分待つとメモリ使用量が一気に増加
- そのまま問題なくロード完了
思っていたよりすんなり動作しました。
初回プロンプトの入力からの遅延
最初の入力時は長い待機があり、モデルの入っているSSDの動作をタスクマネージャーで見ると「モデルの一部再ロードやキャッシュ展開」をしているような挙動。
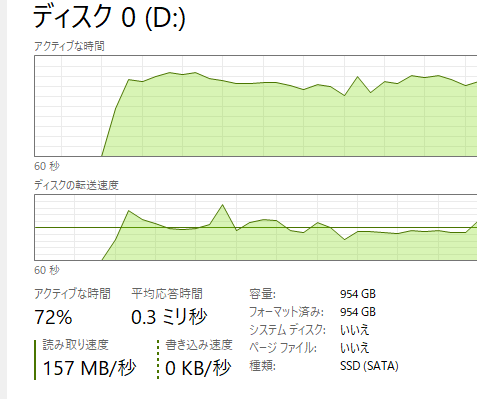
ただし一度準備が済むと、それ以降のプロンプトに対するレスポンスは比較的スムーズでした。
推論性能
- 生成速度: 約 3–4 token/s(20Bは13〜17token/s)
- CPU/GPUの使用率: どちらも上限に張り付かず、メモリ転送やI/Oがボトルネックっぽい
- 実用性: 速度面では正直かなり厳しい
モデルの精度の印象
- 日本語リライト性能
API経由でブログのリライトスクリプトを実行すると高精度で、Gemini 1.5 Flash と比べても遜色がない。20Bと異なりそのまま使える。 - 日本に関する知識
自動リサーチスクリプトをAPI経由で動かして日本国内に関する情報をリサーチさせると頻繁にハルシネーションが起きる。Wikipediaファクトチェックを組み入れてもGPT-OSS側でノイズが強くなり、あり得ない回答になる。20Bと120Bで大差なく、日本固有の情報には弱め。 - 応答品質
120Bは一貫性・推論力が明らかに高く、「知性の厚み」を感じられる。
まとめ
- 動作検証: RTX4070(VRAM 12GB)+ RAM 64GB でもロード可能
- 性能: 3–4 token/s と実用には遅すぎる
- 知識: 日本の情報に関してはまだ限定的
- 活用範囲: 研究・遊び用には面白いが、プロダクション利用は非現実的
- 120Bのインテリジェンスは高いのでAPI経由で時間をかけて放置でいい小難しい処理をさせるならアリ
「ローカルで120B級のモデルが動作する」こと自体はインパクト大ですが、実際に触ってみると速度の壁が大きく、この環境では「技術者が遊ぶには楽しい実験素材」というポジションに収まりそうです。西川善司氏のようにDDR5 RAM 96GBの載るPCや80万円のマックブックプロとかを用意できれば実務にも耐えうるローカルAIが構築できるでしょう。